Methodology
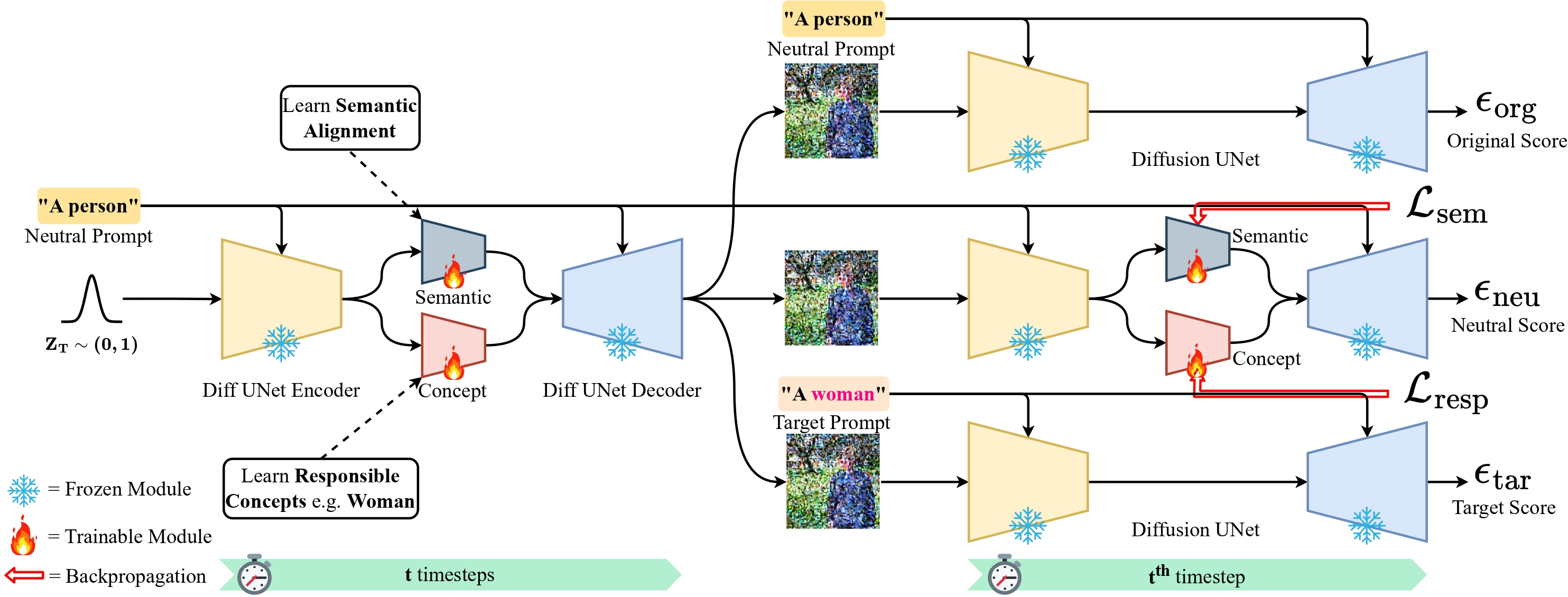
The rapid advancement of diffusion models has enabled high-fidelity and semantically rich text-to-image generation; however, ensuring fairness and safety remains an open challenge. Existing methods typically improve fairness and safety at the expense of semantic fidelity and image quality. In this work, we propose RespoDiff, a novel framework for responsible text-to-image generation that incorporates a dual-module transformation on the intermediate bottleneck representations of diffusion models. Our approach introduces two distinct learnable modules: one focused on capturing and enforcing responsible concepts, such as fairness and safety, and the other dedicated to maintaining semantic alignment with neutral prompts. To facilitate the dual learning process, we introduce a novel score-matching objective that enables effective coordination between the modules. Our method outperforms state-of-the-art methods in responsible generation by ensuring semantic alignment while optimizing both objectives without compromising image fidelity. Our approach improves responsible and semantically coherent generation by 20% across diverse, unseen prompts. Moreover, it integrates seamlessly into large-scale models like SDXL, enhancing fairness and safety.


@inproceedings{NEURIPS2025_3cb4afdb,
author = {Vadakkeeveetil Sreelatha, Silpa and Nag, Sauradip and Awais, Muhammad and Belongie, Serge and Dutta, Anjan},
booktitle = {Advances in Neural Information Processing Systems},
editor = {D. Belgrave and C. Zhang and H. Lin and R. Pascanu and P. Koniusz and M. Ghassemi and N. Chen},
pages = {42551--42583},
publisher = {Curran Associates, Inc.},
title = {RespoDiff: Dual-Module Bottleneck Transformation for Responsible \& Faithful T2I Generation},
url = {https://proceedings.neurips.cc/paper_files/paper/2025/file/3cb4afdb1f00d8c15cfdcd134eb8bfd6-Paper-Conference.pdf},
volume = {38},
year = {2025}
}