Abstract
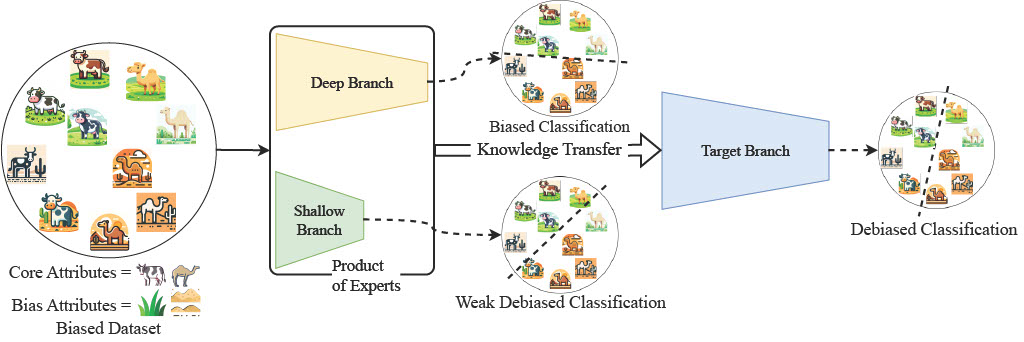
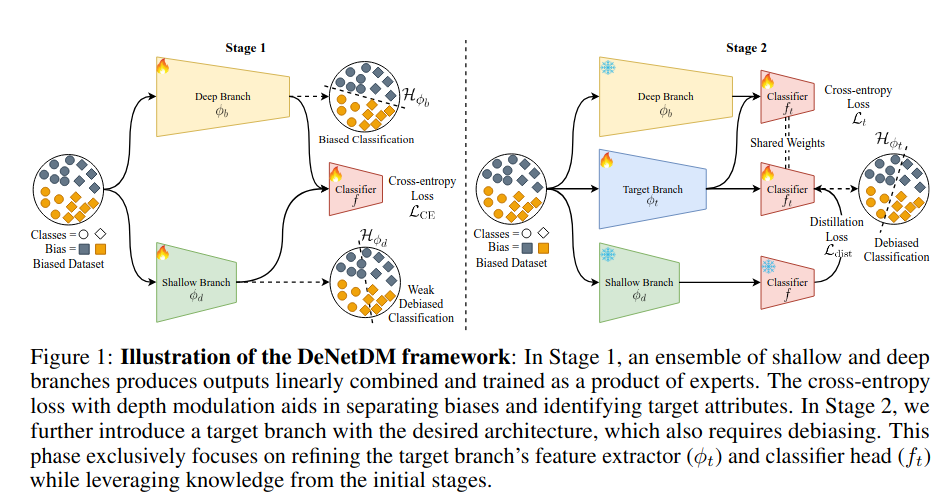
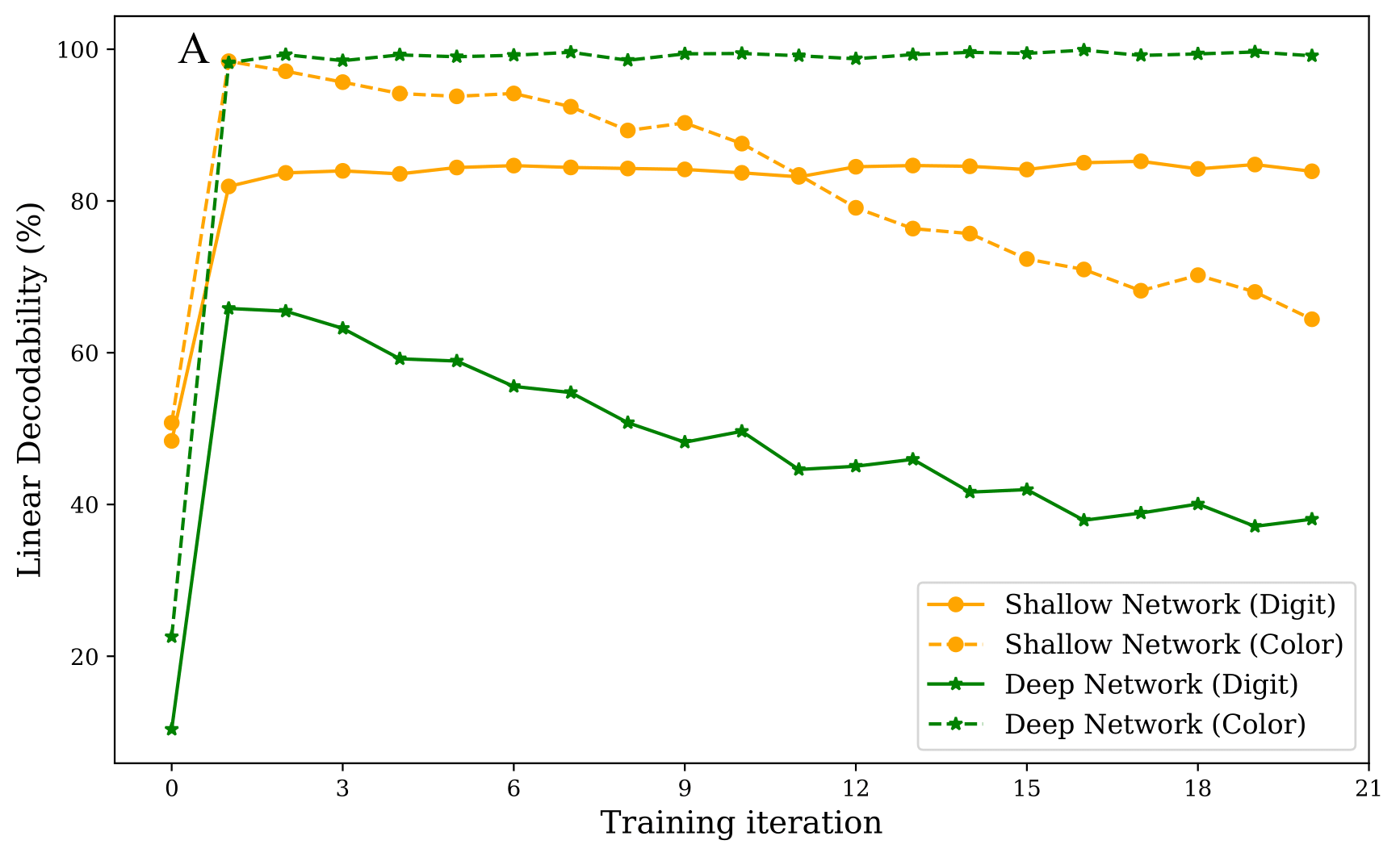
Neural networks trained on biased datasets tend to inadvertently learn spurious correlations, hindering generalization. We formally prove that (1) samples that exhibit spurious correlations lie on a lower rank manifold relative to the ones that do not; and (2) the depth of a network acts as an implicit regularizer on the rank of the attribute subspace that is encoded in its representations. Leveraging these insights, we present DeNetDM, a novel debiasing method that uses network depth modulation as a way of developing robustness to spurious correlations. Using a training paradigm derived from Product of Experts, we create both biased and debiased branches with deep and shallow architectures and then distill knowledge to produce the target debiased model. Our method requires no bias annotations or explicit data augmentation while performing on par with approaches that require either or both. We demonstrate that DeNetDM outperforms existing debiasing techniques on both synthetic and real-world datasets by 5%.